
Exporting your FilmAffinity profile to a .csv file using R.
Published:
Updated May 14th 2024: the code stopped working after FilmAffinity changed the way ratings are shown. A small change in the code was needed to take this into consideration. Thanks to those who emailed me about it!
Yesterday, I decided to start using a different web service to manage my activity as a moviegoer. I have been using FilmAffinity (the Spanish hub for film snobbery) for the last seven years. The platform has been in desperate need for an update, and I was missing the social side of the whole experience. Therefore, I created a Letterboxd account, but I faced the problem of importing all my movies. A quick Google search returned several Python-based solutions, but all of them seemed to be lacking something. Some scripts I could just not make work due to FilmAffinity having changed certain bits of their own HTML code, and some of them were written with the Spanish version of FilmAffinity in mind. This wouldn’t be too important if the titles were the same in all languages, but the Spanish version of FilmAffinity shows the Spanish/Latin American translation of the movie. Being Letterboxd an English-language platform, this means that a good chunk of the movies I had watched could not be automatically imported. After trying to modify some Python scripts made by someone else, I decided to write my own script in R (which I am more comfortable with).
The idea is to go through every page in my profile and extract relevant information about the movies that I’ve watched in order to generate a compatible .csv file. (The fact that it’s for Letterboxd does not really impact the process at all, except for the names used in the .csv file columns).
We will need, at least, three libraries:
library(xml2)
library(rvest)
library(stringr)
The first two libraries will make our life easier by reading the source code of a specified URL. The stringr library will be useful when we need to manipulate entry names. We also need to know which profile we will be getting data from:
id = "958982"
pages = 20
The user ID can be checked in the URL of the user’s profile page, and the number of pages to scrap can be seen at the bottom of the page. Therefore, the URL to scrap will be:
url = paste("https://www.filmaffinity.com/en/userratings.php?user_id=",id,sep="")
(Notice the /en/ we’re using the English version of the site). We will need only two columns to identify the movie (Name and Director) and one to store our rating (Rating10, as specified by Letterboxd, since our marks are on a scale from 1 to 10). We create a data frame:
df = as.data.frame(matrix(data=NA,ncol=3,nrow=pages*50))
The next step is to go through every page, extracting the list of names, directors and ratings. Once that’s done, we need to format everything properly. Checking FilmAffinity’s source code, movie names (as well as those of TV shows and TV show episodes) are contained in a div tag with class mc-title. The director/s are contained in a div with class mc-director, and the rating is stored in a div with class ur-mr-rat. But for some reason the rvest package has trouble finding ratings; luckily we can take advantage of the embedded .png file showing the number of stars (representing our rating of the movie), which is stored in a div with class ur-mr-rat-img. Therefore:
for(i in 1:pages) {
url2 = paste(url,"&p=",i,"&orderby=4",sep="")
rawinfo = read_html(url2)
#Read titles, directors, ratings
titles = html_nodes(rawinfo, ".mc-title")
directors = html_nodes(rawinfo, ".mc-director")
ratings = html_nodes(rawinfo, ".ur-mr-rat-img")
for(j in 1:length(directors)) {
(...)
}
}
Gives us the list of titles, directors and ratings in every page. (The dot before the class name is necessary, since this is how we differentiate classes from ID’s in HTML, two similar concepts with different uses). In the innermost for loop, whose content is here omitted, we format each one of those. Particularly, titles should be editted so that no commas remain (could cause conflicts in the resulting comma separated file). The directors can be just extracted without further formatting. The code looks messy, but it’s been generated using RStudio’s navigator —I did not spend time writting the code to extract particular entries—.
title = xml_attrs(xml_child(titles[[j]], 1))[["title"]]
title = sub(",","",title)
director = xml_attrs(xml_child(xml_child(xml_child(directors[[j]], 1), 1), 1))[["title"]]
The URL of the star rating can be edited to get just the number. Since URLs have the format /imgs/myratings/X_.png, one can write:
rating = sub("https://filmaffinity.com/images/myratings/","",xml_attrs(xml_child(ratings[[j]], 1))[["src"]])
rating = sub(".png","",rating)
rating = sub("_","",rating)
rating = as.integer(rating)
And we now have our rating as an integer. The only remaining problem is that Letterboxd does not index TV content. Therefore, we can use FilmAffinity’s title formatting, which includes notes like (TV series), to avoid adding those entries to our data frame:
if(!str_detect(title,"TV")) df[(i-1)*30+j,] = c(title,director,rating)
Finally, we just add the right names to the columns in our dataframe, clean it a bit (taking those NA’s entries out) and save the result in a .csv file:
colnames(df) = c("Title","Directors","Rating10")
df = na.omit(df)
write.csv(df,file="output.csv",row.names=F,quote=F)
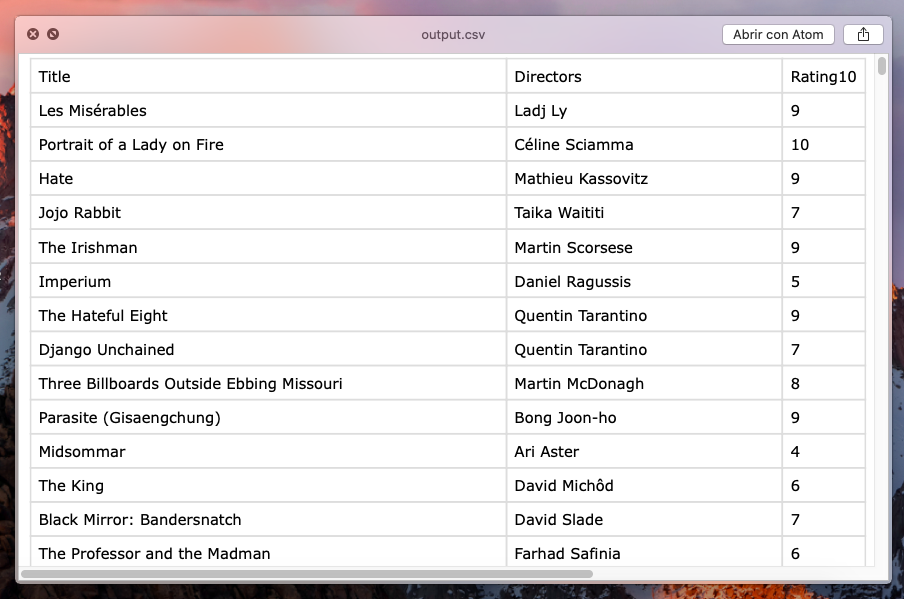
The result is pretty good: out of 540 movies in my profile, I could import 538 with no problem (99.6% success rate!).
The code is available in my GitHub profile.